Aunque sabemos que CentOS7 ya tiene sus días contados, hay ciertas aplicaciones que todavía dependen de esta distro por lo que aun es necesario instalarla, en esta caso en particular estoy instalando en un servidor hp ProLiant G5 también fuera de soporte y al momento de iniciar el proceso de instalación no reconoce los discos, por lo que hay que realizar un procedimiento bastante sencillo y es cargar o indicarle al kernel que utilice unas librerías especificas del Smart array p400 y p400i.
Cabe destacar que sirve para cualquier generación en mi caso lo he probado con G5 y G6 tanto DL380 como DL360
1. Inserte el USB de instalación de Centos7
2. Para ingresar a la interfaz de instalación seleccionada, seleccione primero, luego presione la tecla «Tab», ingrese el modo de inicio de edición del kernel
3. Agregue parámetros de inicio en la línea de comando hpsa.hpsa_simple_mode=1 hpsa.hpsa_allow_any=1 (notas: hay espacios entre los parámetros)
Luego de esto se presiona Enter para continuar con la instalación de manera habitual.
4. Reinicie el sistema cuando haya terminado. También debe modificar los parámetros de inicio. En la interfaz de selección del kernel, presione la tecla «e» para editar.
encuentre «….rhgb quiet» Tal declaración, agregue después de hpsa.hpsa_simple_mode=1 hpsa.hpsa_allow_any=1 Dos parámetros, luego ” ingrese “ start-up
(La imagen es una captura de pantalla de la máquina virtual, el contenido es diferente, solo la interfaz)
5. Después de ingresar al sistema, debe editar el archivo /etc/default/grub para iniciar la carga automática
GRUB_TIMEOUT=5
GRUB_DEFAULT=saved
GRUB_DISABLE_SUBMENU=true
GRUB_TERMINAL_OUTPUT=»console»
GRUB_CMDLINE_LINUX=»……( notes : Different systems have different contents ) rhgb quiet hpsa.hpsa_simple_mode=1 hpsa.hpsa_allow_any=1«
Recientemente me toco crear un cluster con 3 equipos para correr mysql HA con pacemaker y corosync en redhat, por lo que estoy haciendo este pequeño howto el cual se puede adaptar a cualquier distro, así que vamos al grano.
Lo primero que debemos instalar son los paquetes necesarios pacemaker, corosync mysql en los 3 nodos
Hasta aquí tendremos nuestro cluster corriendo y debemos iniciar con la configuración del cluster para mysql
Lo primero que debemos hacer es deshabilitar los stonith que es el método de seguridad del cluster y colocando el false le indicamos al cluster que no falle o no alerte si algunos de nuestros nodos se desconectan de manera no apropiada.
[root@nodo1 root]# pcs property set stonith-enabled=false
Para que el cluster funcione deben existir 2 servicios mysql-ser-clone y mysql-vip, el primero clona los servicios mysql en todos los nodos y el segundo asigna una ip virtual flotante la cual será utilizada por el nodo que asuma el master en ese momento, por lo que debemos configurar el cluster con una ip del mismo segmento de los 3 nodos.
Ahora definiremos los contraints y esto son las preferencias para asumir el master del cluster, dichas preferencias van del 100 al 0, 100 como la mayor prioridad y 0 como la de menor prioridad, de tal modo que si tenemos más de 3 nodos podemos darle las siguientes prioridades Ejemplo: nodo1=100, nodo2=75, nodo3=50, nodo4=25, nodo6=0
Ya con todo esto tendremos configurado nuestro cluster con 3 nodos y podemos verificar con el sigueinte comando.
[root@nodo1 root]# pcs status
Cluster name: mysql_cluster
Cluster Summary:
* Stack: corosync
* Current DC: nodo03 (version 2.0.X) - partition with quorum
* Last updated: Mon Feb 21 17:21:29 2022
* Last change: Mon Feb 21 15:31:15 2022 by hacluster via crmd on nodo03
* 3 nodes configured
* 4 resource instances configured
Node List:
* Online: [ nodo01 nodo02 nodo03 ]
Full List of Resources:
* Resource Group: mysql:
* mysql_vip (ocf::heartbeat:IPaddr2): Started nodo01
* Clone Set: mysql_ser-clone [mysql_ser]:
* Started: [ nodo01 nodo02 nodo03 ]
Daemon Status:
corosync: active/enabled
pacemaker: active/enabled
pcsd: active/enabled
[root@nodo01 root]#
Si todo ha salido bien nos debe salir algo parecido a lo anterior, que nos indicara quien está como master y quienes son los esclavos.
Para que mysql tenga alta disponibilidad debemos configurar a nivel de DB para que se repliquen entre los nodos independientemente del cluster y para ello debemos habilitar 2 opciones en mysql.
Lo primero es loguearnos desde la consola o manejador de DB de nuestra preferencia apuntando al nodo1.
Configuraremos nuestro cluster para que sea HA, lo que quiere decir que independientemente del nodo que este activo, los datos se replicaran en todos los nodos y para ello es importante crear un usuario para la réplica y su password a nivel de mysql en todos los nodos ya que este es el encargado de realizar la replicación de los datos y con el comando grant replication indicamos que es el usuario encargado de realizar la replicación en mi caso use replicauser, ustedes pueden usar el que gusten.
[root@nodo01 root]# mysql -u root -p
mysql> create user replicauser;
mysql> ALTER USER 'replicauser'@'%' IDENTIFIED BY 'new_passowrd';
mysql> grant all on *.* to 'replicauser'@'%'; mysql> grant replication slave on *.* to 'replicauser'@'%';
Para configurar mysql HA realizaremos el siguiente procedimiento.
[root@nodo01 root]# mysql -u root -p
mysql> show master status;
+---------------+----------+--------------+------------------+-------------------+
| File | Position | Binlog_Do_DB | Binlog_Ignore_DB | Executed_Gtid_Set |
+---------------+----------+--------------+------------------+-------------------+
| binlog.000008 | 5490 | | | |
+---------------+----------+--------------+------------------+-------------------+
1 row in set (0.00 sec)
mysql>
Estos nos los datos de nuestro servidor master de mysql y que debemos configurar en el servidor esclavo para que se realicen las réplicas, ahora sabiendo los parámetros del File y Position nos vamos al servidor esclavo nodo2
Vemos la salida anterior del comando slave en mi caso ya está configurado, pero si quisiera cambiar algún parámetro o en caso de que sea la primera configuración ejecutaríamos el siguiente comando dentro de la consola mysql.
Iniciamos el esclavo con start slave desde la consola mysql y deberíamos ver una línea como estas: Slave_SQL_Running_State: Replica has read all relay log; waiting for more updates
Lo que nos indica que se está ejecutando la replica de DB en mysql, para probar basta con crear una db o una tabla o hacer un insert en alguna tabla existente y podremos ver los datos replicados.
En nuestro caso como queremos que se replique en todos los nodos, debemos realizar el procedimiento de master y slave en cada uno para lograr nuestro objetivo, esto porque mysql puede ser master y esclavo al mismo tiempo.
Nuestro escenario es:
nodo1 ip 10.10.1.101, nodo2 ip 10.10.1.102, nodo3 ip 10.10.1.103
nodo 1 es master del nodo2 y esclavo del nodo3.
nodo2 es master del nodo3 pero esclavo del nodo1.
nodo3 es master del nodo1 pero esclavo del nodo2
por lo que se cumple el ciclo que andamos buscando de alta disponibilidad de los datos.
Algunos comandos para administración de nuestro cluster
pcs status para saber el estado de nuestro nodo y del cluster
pcs config para saber la configuración del cluster
pcs cluster stop para para el cluster en un nodo en especifico
pcs cluster stop –all para para todos los nodos del cluster y los servicios de mysql
pcs node standby nodo1 para mover los servicios al nodo2.
pcs node unstanby nodo1 para regresar los servicios al nodo1
A mi particularmente me gusta utilizar mas pcs cluster stop ya que esto baja tambien el servicio de mysql y para hacer cambios es ideal ya que no hay ningun servicio del cluster corriendo.
NOTA: Es necesario que el archivo /etc/hosts este correctamente configurado en caso de no tener un dns para que se pueda resolver los nombres de los nodos de forma correcta.
La gran mayoría de las veces en Open Source todo funciona bien hasta que tiene que hacer una migración. Acabo de realizar una migración de un Zimbra 5.0.x a una versión 8.0.x. El salto de versiones es muy importante y la gran mayoría de las veces en zimbra teniendo muchos usuarios la migración podría tardar días, además al hacer un upgrade directamente en el servidor de producción hay que hacerlo en versiones sucesivas y podría fallar la instalación al comprobar las bases de datos.
Después de varias pruebas y varias consultas con san google he conseguido migrar todas las cuentas y todos los buzones. A continuación pongo los datos y los pasos a seguir.
Lo primero que debemos hacer es instalar el servidor nuevo, en mi caso en un hardware nuevo virtualizado con xen 6.0, cabe destacar que no es necesario mantener la misma versión de SO en mi caso uso redhat 5 y el nuevo esta en redhat 6.5, ya que la versión 8.x de zimbra no tiene soporte para redhat5 y para ser sincero no probé instalar zimbra 8 en redhat 5 por cuestiones de tiempo cuando lo haga lo público y les cuento el resultado.
No voy a detallar paso a paso la instalación del SO ni del zimbra puesto que es algo intuitivo y si ya estamos buscando cómo migrar ya debemos saber ambos puntos.
1. – En la página inicial de la consola de administración del nuevo zimbra, haz click en “3. Migración y coexistencia“
2. – En el asistente de importación que se abre, se pregunta qué tipo de servidor se va a importar y si se van a importar cuentas y/o correos.
En nuestro caso vamos a elegir que el origen es un Zimbra y que vamos a importar tanto las cuentas como el correo.
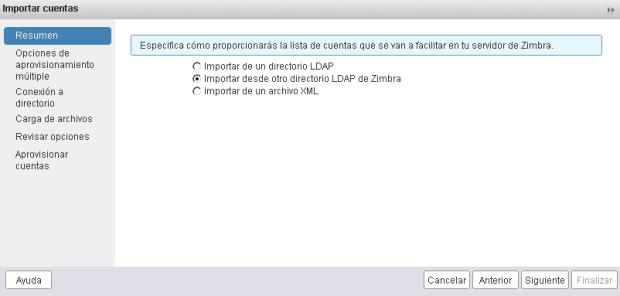
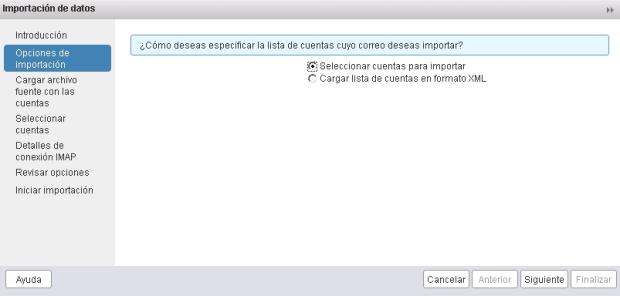
3.- Al pulsar en Siguiente, podremos elegir si lo importamos desde un directorio LDAP (o un Directorio Activo), desde un LDAP de Zimbra o bien un XML.
Vamos a elegir LDAP de Zimbra.
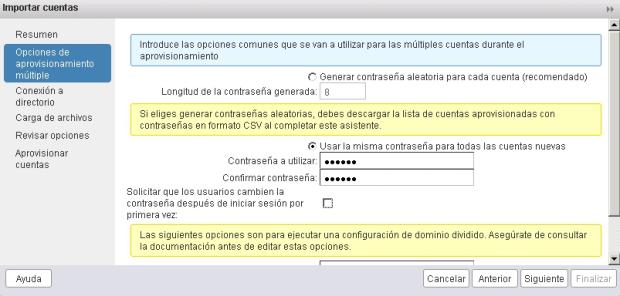
4.- Ahora nos preguntará por las claves. Aquí me detengo un poco y explico.
En esta instalación la autenticación se hará mediante directorio activo, es decir, pongamos las claves que pongamos, cuando terminemos todo este proceso las claves serán las que tengan los usuarios en el AD.
Para esta instalación he puesto que la clave sea qwerty y que no cambien la contraseña.
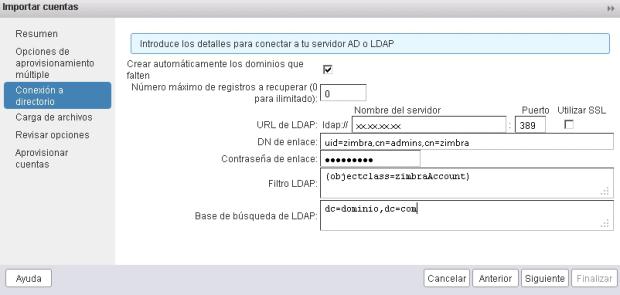
5.- Ahora debemos decirle desde donde va a tener que coger los usuarios. Ponemos la IP del Zimbra antiguo, el DN de enlace, su Contraseña, el Filtro LDAP y la Base de búsqueda.
El DN de enlace la podemos sacar en el zimbra viejo. Como usuario zimbra, ejecutamos el comando:
En la Base de búsqueda debemos poner el dominio en su formato dc=dominio,dc=com
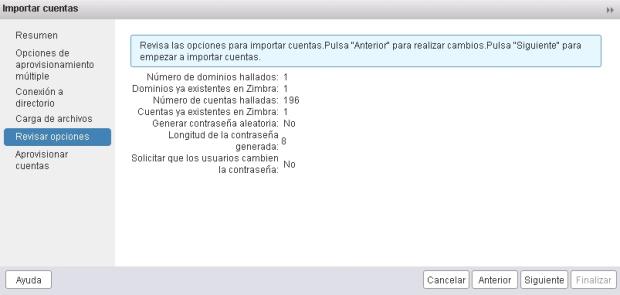
6.- Si hemos puesto todos los datos bien, nos mostrará la información encontrada en el antiguo Zimbra. Dominios encontrados, cuentas, etc…
7.- Al dar Siguiente comenzará la importación de las cuentas. SOLO de las cuentas, es decir, crea una cuenta de correo en el nuevo Zimbra con los datos del antiguo pero creará un buzón vacío. El correo se importará más tarde.
Si no nos da ningún error, nos aparecerá algo como esto.
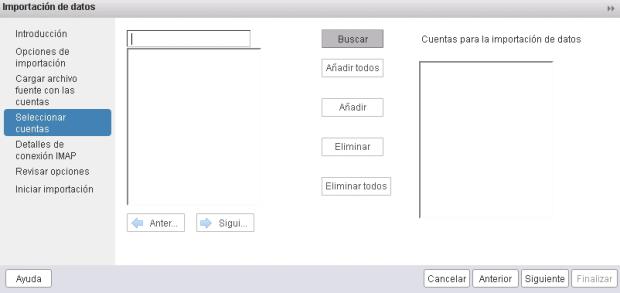
8.- Ahora vamos a intentar (y digo bien, INTENTAR) importar los buzones. Pulsa en Siguiente y vamos a seleccionar las cuentas a importar.
9.- Si se pulsa sobre Buscar, aparecerá todas las cuentas en bloques de 50). Si tienes más de 50 usuarios, una vez que los añadas a la ventana de la derecha, pulsa en el botón Siguiente para ver los siguientes 50. Así hasta que en la ventana de la derecha veas todos tus usuarios. En mi caso 200.
10.- Al pulsar siguiente nos preguntará las características del Zimbra origen, es decir, desde donde se va a importar.
Por defecto, conexión SSL.
IP y puerto IMAP Origen.
Usuario root y contraseña de root del Zimbra Origen.
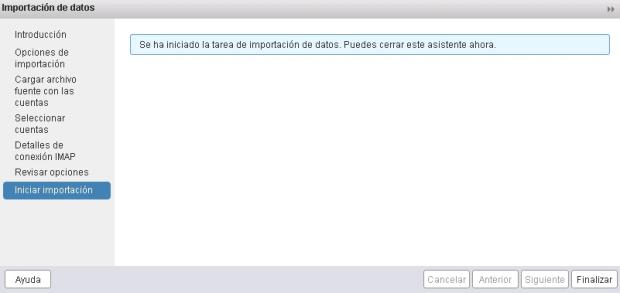
11.- Si hemos puesto todos los datos bien, pasará a la siguiente pantalla, indicando que la tarea de importación ha comenzado.
12.- Podemos pulsar Finalizar ya que el proceso se seguirá haciendo en segundo plano.
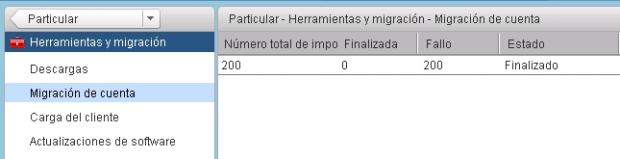
Pasado el tiempo nos daremos cuenta que falla y no importa ningún buzón.
Por lo general siempre da fallo cuando intenta pasar los buzones pero no es para preocuparse ya que zimbra cuenta con una herramienta de migración vía consola.
Esta herramienta de migración se llama zmztozmig y es la que utilizaremos para poder importar todos los mensajes.
Debemos editar el archivo zmztozmig.conf en el zimbra nuevo, el cual se encuentra en la siguiente ruta:
# vim /opt/zimbra/conf/zmztozmig.conf
Se debe cambiar los parámetros siguientes:
# Fuente ZCS servidor IP / nombre, nombre de usuario admin y la contraseña, puerto del servidor
SourceZCSServer: ejemplo.dominio.com o también podemos colocar la IP
SourceAdminUser: Admin ( Si al igual que yo por seguridad tiene el usuario admin deshabilitado un usuario con permiso de administración también servirá)
SourceAdminPwd: Contraseña (del admin o el usuario con permiso de administración en zimbra)
SourceAdminPort: 7071 (por defecto)
# Destino / Target ZCS servidor IP / nombre, nombre de usuario admin y la contraseña, puerto del servidor
TargetZCSServer=zcs2.example.com TargetAdminUser=Admin TargetAdminPwd=pwdpwd TargetAdminPort=7071 TargetZCSServer: Nuevo_servidor (Nombre o IP)
TargetAdminUser: Admin ( Un usuario con permiso de administración servirá)
TargetAdminPwd: Contraseña
TargetAdminPort: 7071 (por defecto)
Este comando te permite ejecutar migraciones simultáneas pero como queremos que se haga bien y no rápido puesto que nuestro servidor antiguo en producción todavía esta funcionado lo dejaremos en uno.
# Tareas a ejecutar simultáneamente
Threads=1
# ¿Quieres guardar archivos tar con éxito la migración de buzones después-VERDADERO / FALSO
KeepSuccessFiles=TRUE
Esta opción le permite guardar una copia de cada cuenta (en un archivo comprimido .tgz), en la ruta
SuccessDirectory = /tmp/ztozmig/success/
Si no quieres guardar estos archivos después de la importación, lógicamente, cambia el parámetro anterior a “FALSE”.
Si se va a cambiar el dominio de correo a uno nuevo, tendrás que cambiar las siguientes líneas. Si no hay cambio de dominio, y solo cambio de servidor -como es mi caso actual-, TIENES QUE COMENTAR estas líneas y pasar al parámetro Cuentas.
# Resolver=saltar
DomainMap=zcs1.example.com zcs2.example.com
Esta línea debe tener el dominio Origen, seguido del dominio Destino. Es decir, si pasamos de un dominio dominio.com a otro cambiado.com, pondremos:
DomainMap=dominio.com cambiado.com
Ahora debemos especificar que cuentas se van a importar.
Tenemos 2 opciones. O migrar todas o especificar las cuentas que queramos. En el primer caso, pondremos ALL, y si no, pondremos todas las cuentas en una solo línea separadas por comas. En caso de poner Cuentas=ALL tendremos que utilizar por narices la opción anterior (DomainMap)
En mi caso, han sido casi 400 cuentas por lo que he puesto todas las cuentas separadas por comas y por lotes para hacer más fácil la migración y como no tengo prisa.
Una vez modificado a nuestro gusto el archivo lo guardamos y con el usuario zimbra ejecutamos dicho script.
Después de importar se muestra datos como a continuación
El número de cuentas en servidor en este caso 1, el número de cuentas importadas con éxito 1, el número de cuentas que fallaron 0 y la duración de la importación 5.863 segundos, puesto que era una cuenta con pocos correos.
Y siguiendo estos pasos aseguraremos una migración exitosa, aunque lo probe solo con estas 2 versiones estoy seguro que puede funcionar con cualquier versión de zimbra.











Debe estar conectado para enviar un comentario.